 Media Intelligence
Media Intelligence
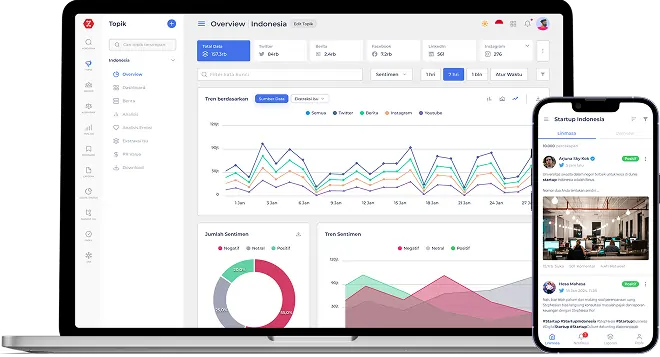
 Research Intelligence
Research Intelligence
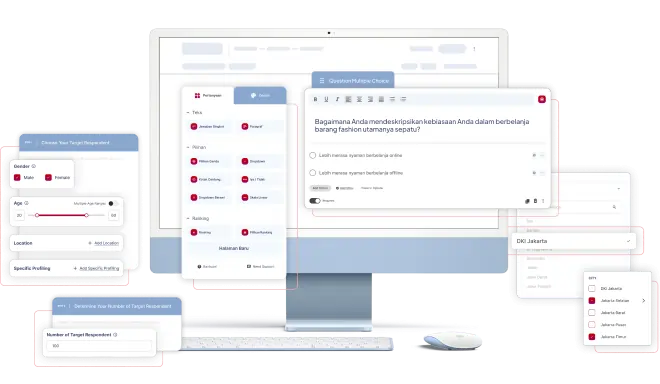
 Location Intelligence
Location Intelligence
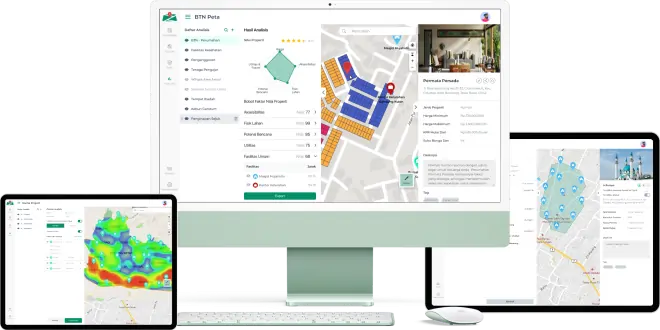
 News Analysis
News Analysis  Solution By Departement
Solution By Departement 
 Solution By Industry
Solution By Industry 

 Company
Company 
Apa Itu Scraping Data? Beda Dengan Crawling?

Bayu Septian
22 May 2023 18:30

Dalam era digital yang semakin maju, pengumpulan data telah menjadi suatu kebutuhan penting untuk berbagai keperluan, seperti penelitian, analisis pasar, pengembangan produk, dan masih banyak lagi. Untuk memperoleh data yang diperlukan, dua teknik yang sering digunakan adalah scraping data (data scraping) dan crawling data (web crawling).
Meskipun sering digunakan secara bergantian, kedua teknik ini sebenarnya memiliki perbedaan dalam pendekatan dan tujuan penggunaannya. Artikel ini akan menjelaskan secara rinci apa itu scraping data dan bagaimana perbedaannya dengan crawling data.
Scraping Data
Hal tersebut merujuk pada proses pengumpulan data dari sumber-sumber tertentu di web. Teknik ini melibatkan ekstraksi informasi secara otomatis dari halaman web menggunakan program atau algoritma yang disebut “web scraper”. Web scraper ini membantu mengambil informasi yang terstruktur dari halaman web dan menyimpannya dalam format yang dapat digunakan lebih lanjut, seperti spreadsheet atau database.
Web scraper bekerja dengan memuat halaman web, menganalisis struktur HTML atau XML, dan mengidentifikasi elemen data yang diperlukan. Elemen data ini dapat berupa teks, tabel, gambar, atau informasi lainnya. Setelah data diidentifikasi, web scraper akan mengekstraknya secara otomatis dan menyimpannya dalam format yang berguna.
Scraping data sering digunakan untuk mengumpulkan data dalam skala besar atau dari beberapa sumber yang berbeda. Misalnya, jika Anda ingin mengumpulkan data harga produk dari beberapa situs e-commerce, Anda dapat menggunakan scraping data untuk secara otomatis mengambil data tersebut dari masing-masing situs dan menyimpannya dalam database yang dapat digunakan untuk analisis lebih lanjut.
Baca Juga Gangguan “Instagram Down”, Apa Penyebabnya?
Namun, penting untuk dicatat bahwa scraping data harus dilakukan dengan etika dan menghormati kebijakan privasi dan hak cipta. Penggunaan scraping data yang tidak etis atau melanggar hukum dapat memiliki konsekuensi serius.
Crawling Data
Crawling data, di sisi lain, adalah proses pengumpulan informasi secara sistematis dari berbagai halaman web. Teknik ini melibatkan penggunaan “web crawler” atau “spider” yang secara otomatis menjelajahi dan mengindeks halaman web yang terhubung dalam jaringan internet.
Web crawler bekerja dengan memulai dari satu halaman web, mengikuti tautan yang ada di dalamnya, dan terus melanjutkan proses ini secara berulang untuk halaman-halaman baru yang ditemukan. Tujuan utama dari crawling data adalah mengumpulkan sebanyak mungkin informasi dari berbagai sumber.
Crawling data umumnya digunakan oleh mesin pencari seperti Google, Bing, dan lainnya untuk mengindeks halaman web dan menyajikan hasil pencarian yang relevan. Namun, juga dapat digunakan untuk tujuan lain, seperti memperoleh informasi untuk keperluan analisis atau penelitian.
Perbedaan Antara Scraping Data dan Crawling Data
Meskipun scraping data dan crawling data memiliki kesamaan dalam hal pengumpulan informasi dari web, ada beberapa perbedaan utama antara keduanya:
1. Pendekatan Pengumpulan Data:
Scraping data fokus pada ekstraksi informasi yang terstruktur dari halaman web yang dituju. Teknik ini dilakukan dengan mengidentifikasi elemen data yang spesifik dan mengekstraknya secara otomatis.
Crawling data, di sisi lain, berfokus pada pengindeksan dan pengumpulan informasi dari berbagai halaman web secara sistematis. Web crawler mengikuti tautan di halaman web untuk menemukan dan mengumpulkan sebanyak mungkin informasi.
2. Skala dan Jangkauan:
Scraping data biasanya dilakukan dalam skala yang lebih kecil dan terfokus pada sumber data tertentu. Anda dapat mengumpulkan data dari beberapa halaman web atau situs yang ditargetkan.
Crawling data beroperasi dalam skala yang lebih besar dan melibatkan eksplorasi dan pengumpulan data dari berbagai halaman web yang terhubung di internet. Proses crawling data dilakukan secara luas dan menyeluruh untuk mencakup sebanyak mungkin informasi yang tersedia.
Baca Juga Google Bard vs Chat GPT, Siapa Juaranya?
3. Tujuan Penggunaan:
Scraping data sering digunakan untuk mengumpulkan data spesifik yang diperlukan untuk analisis atau keperluan bisnis. Contohnya adalah pengumpulan data harga produk, ulasan pelanggan, atau informasi produk dari beberapa situs e-commerce.
Crawling data digunakan untuk mengumpulkan data dalam skala besar untuk berbagai tujuan. Misalnya, mesin pencari menggunakan teknik crawling untuk mengumpulkan dan mengindeks halaman web guna menyajikan hasil pencarian kepada pengguna.
4. Struktur Data yang Diperoleh:
Scraping data cenderung menghasilkan data yang terstruktur sesuai dengan format yang diinginkan, seperti tabel atau spreadsheet. Informasi yang diekstraksi biasanya sudah terorganisir dengan baik dan siap untuk dianalisis.
Crawling data dapat menghasilkan berbagai jenis informasi, termasuk teks, gambar, video, dan sumber daya lainnya. Data yang dihasilkan mungkin perlu diolah lebih lanjut untuk memperoleh struktur yang terorganisir.
5. Legalitas dan Etika:
Kedua teknik ini harus dilakukan dengan mematuhi aturan hukum dan etika yang berlaku. Beberapa situs web memiliki kebijakan yang melarang penggunaan scraping data atau crawling data tanpa izin.
Penting untuk memperhatikan hak cipta, privasi, dan kebijakan penggunaan data saat melakukan scraping atau crawling. Selalu pastikan untuk memahami dan menghormati kebijakan situs web yang Anda tuju.
Pada akhirnya, keduanya adalah teknik yang berguna untuk mengumpulkan informasi dari web. Pemilihan teknik tergantung pada kebutuhan dan tujuan penggunaan data. Dalam semua kasus, penting untuk melakukannya dengan etika dan mematuhi hukum serta kebijakan yang berlaku.
Related Articles


Memperkuat Strategi Pemasaran E-Commerce Berbasis Lokasi dengan Location Intelligence
24 March 2024 22:50
Memperkuat Strategi Pemasaran E-Commerce Berbasis Lokasi dengan Location Intelligence
24 March 2024 22:49




